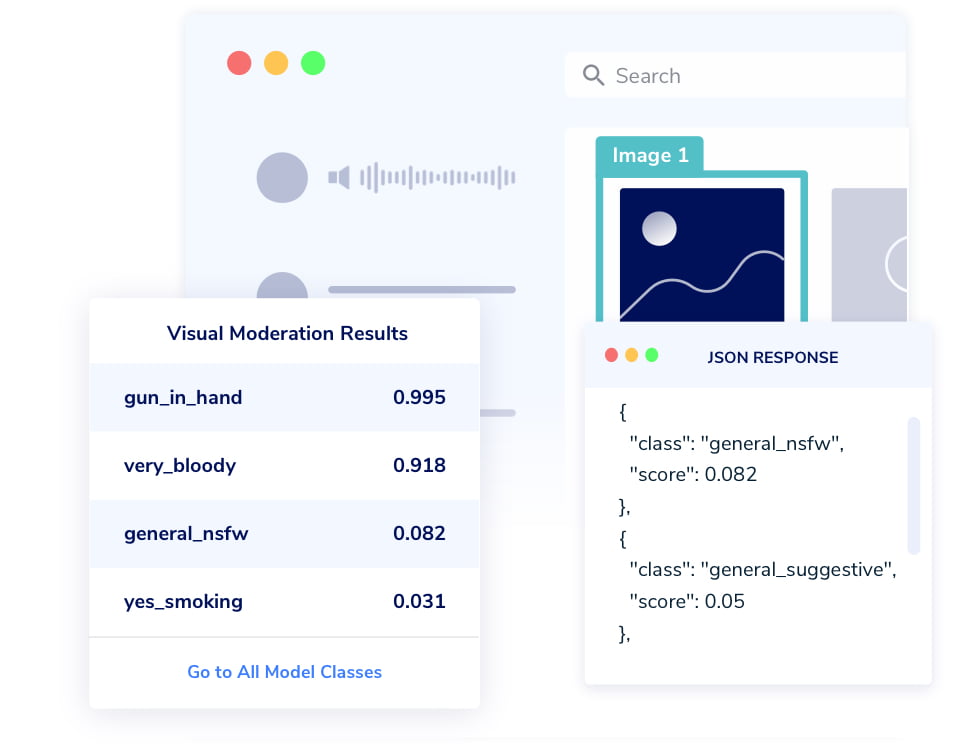
Overview of Hive Models
At Hive, we provide ready-to-go solutions to help companies understand their content. Building these solutions in-house is both expensive and time-consuming for enterprise companies. Our pre-trained AI models offer an efficient, effective alternative that has already been tested and vetted by customers across the world. We work closely with each client to make sure our models are best-suited for their unique use cases, and we welcome requests for new features and products.
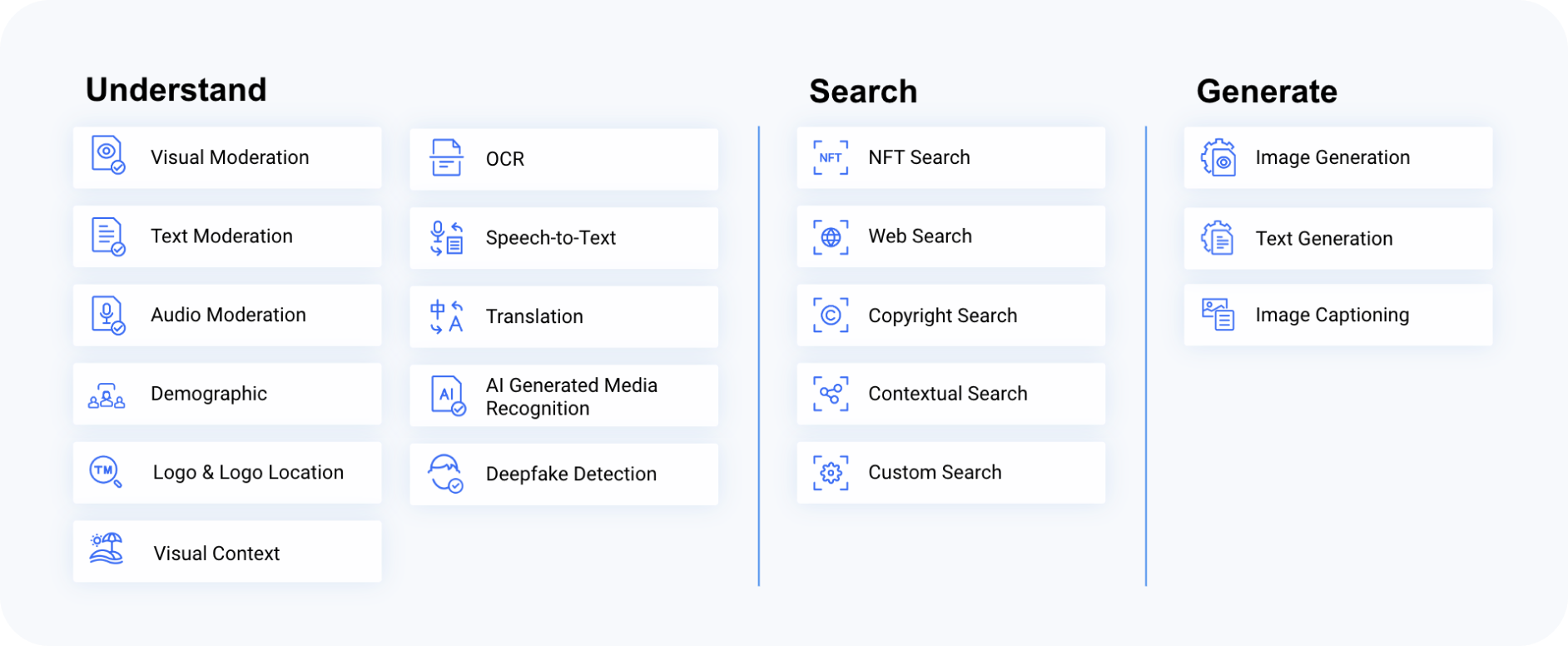
Products
Hive offers 21 different APIs across three different categories: understand, search, and generate.
APIs within the understand category perform a range of functions related to content understanding, from content moderation to logo detection for brand analysis. Using these products, customers can automate their workflows and expand their capabilities by enabling tools like OCR, translation, and speech-to-text.
Our search APIs are powerful tools used to analyze visual similarity and perform large-scale searches across image and video databases. The possible uses of these products include identifying duplicate images across a platform, flagging copyrighted-protected material, and enabling site-wide text-to-image search.
Generate APIs produce new images or text based on some sort of prompt, and can be used to build new generative capabilities into photo editing tools and search engines, make visual content accessible to blind or low-vision users through image descriptions, and inspire designers as they brainstorm new projects.
This documentation provides in-depth descriptions of our products and how to use them. For more general information about each of our APIs and the solutions they provide, please visit our website.