Retrieval Augmented Generation
Use RAG to improve the results of your large language model without re-training
Overview
Embeddings can be used to "augment" Large Language Model deployments. More specifically, the information in an embedding can be searched during inference requests to the large language model (LLM) to supplement the customer request with additional context. This approach is often referred to as Retrieval Augmented Generation.
Retrieval augmented generation (RAG) leverages knowledge stored in a retrieval system to make the output of a large language model more accurate. Before the model generates a response, it first searches this new knowledge base for any information or context that is relevant to the prompt. Any information found is then seamlessly integrated with a generative model and is included as part of the model’s response.
This approach can help address limitations of LLMs. LLMs can be factually incorrect and can "hallucinate" by presenting false information in coherent, convincing ways. Incorporating pre-verified information from an embedding into the LLM request helps to ensure that responses from the model are factually correct.
Augmenting an LLM also allows the embedding information to be easily swapped out. Instead of retraining an LLM with new information each time that information changes, you can simply update the embedding. Once the information is added to the embedding, this additional information will automatically be provided to the LLM.
How to Augment a Deployment
You can augment a deployment either from the embedding detail page or from a model deployment page. Please note that embeddings augment Deployments not Models. This means one model can have multiple deployments that are each augmented with a different embedding.
Currently you can only augment deployments of the "Hive LLM Chat 70B" model. You cannot augment a custom LLM project.
Augment From an Embedding
After you have created an embedding, you can augment any active deployment with that embedding from embedding detail page. To do this, click on Augment Deployment button and select which deployment you want to augment. From here, you can start using your deployment via API as outlined on the Deployments page.
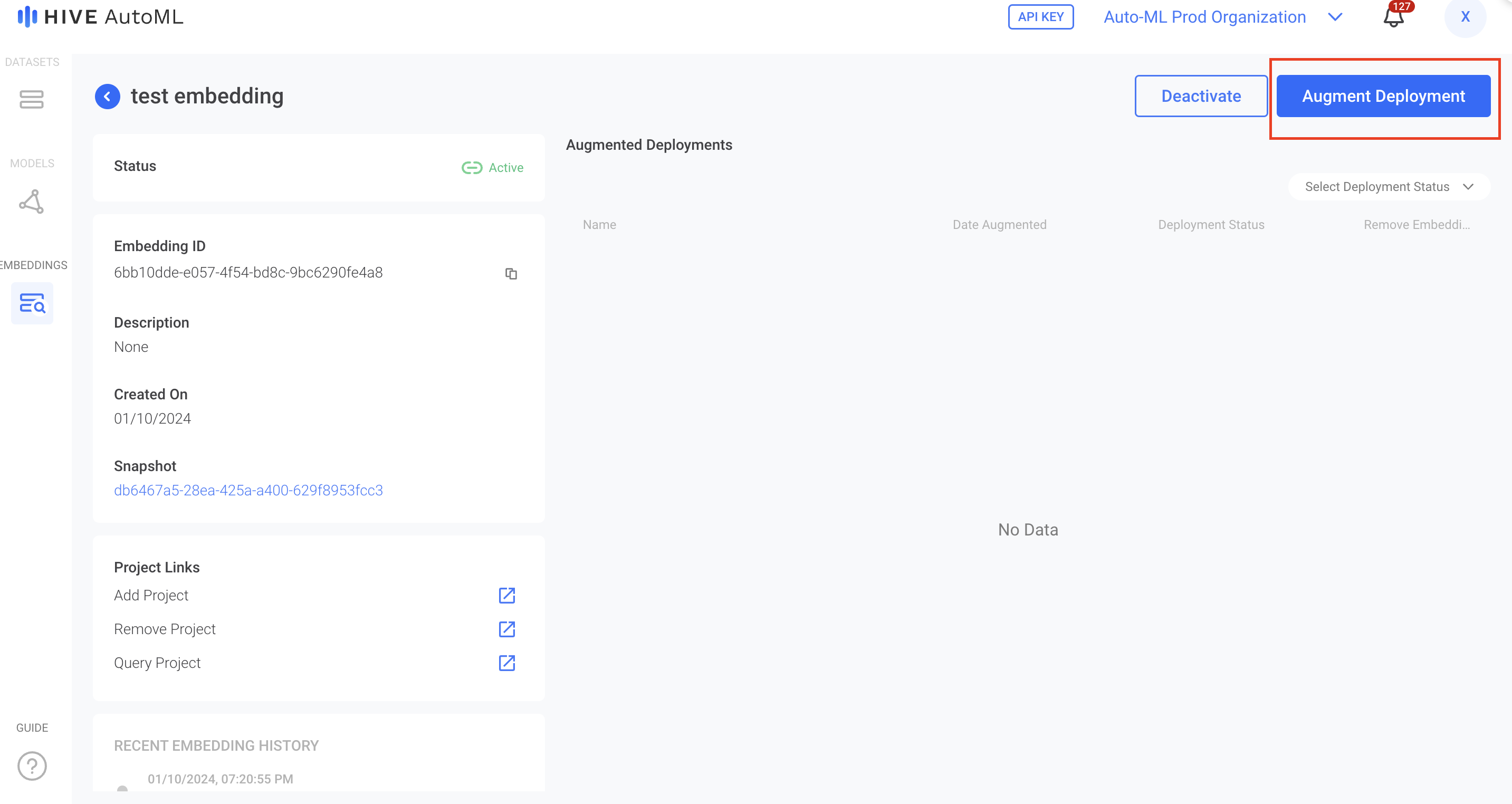
To augment a deployment, select the Augment Deployment button on the top right of the detail page for an individual embedding.
Augment From a Deployment
You can also augment a deployment directly from the Deployments tab of any model's details page. After creating a deployment of the "Hive LLM Chat 70B" model, select the Deployments tab. You will then be able to Add Embedding to the active deployment of your choice.
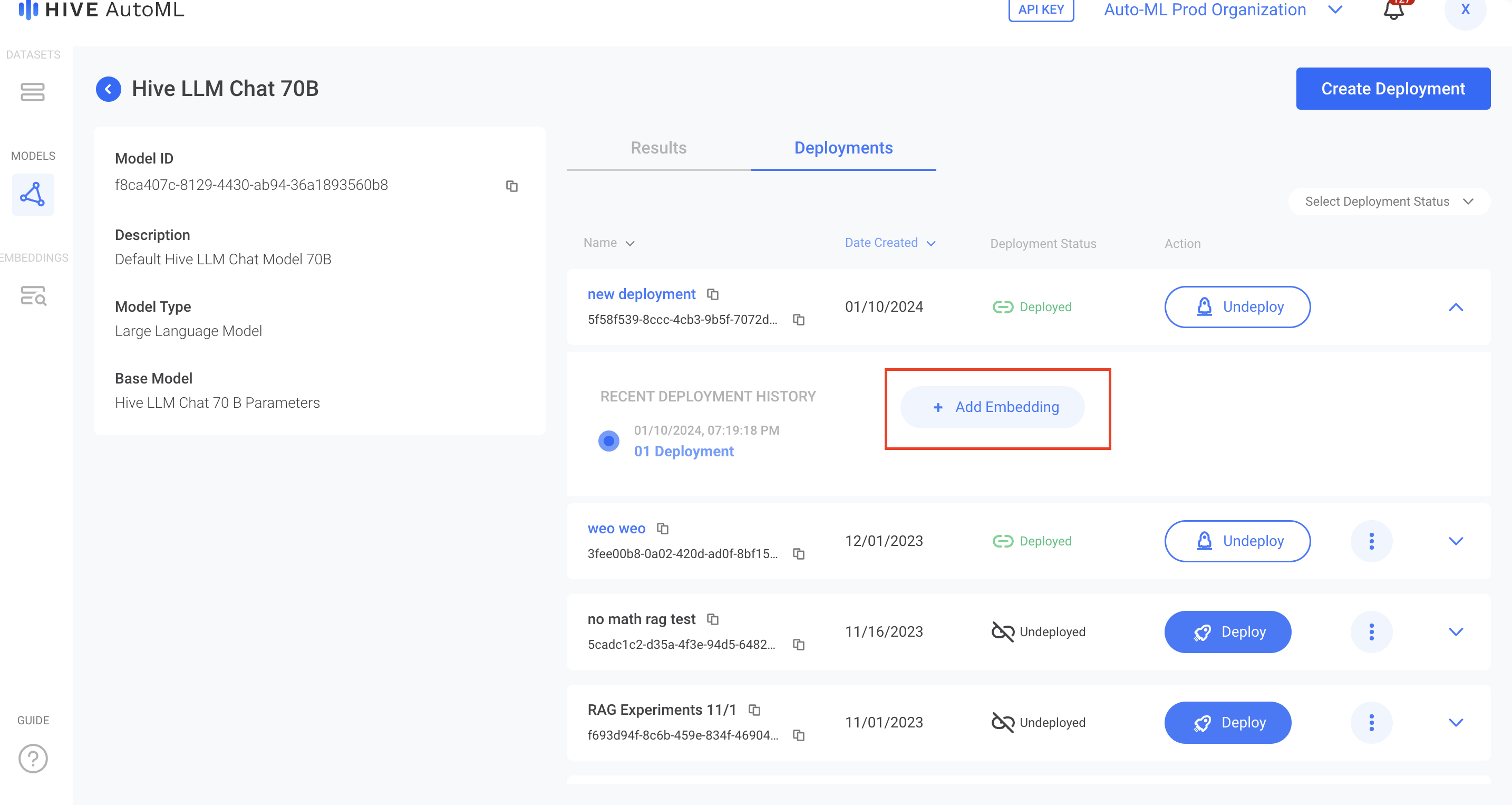
To augment a deployment, select the Add Embedding button that appears after expanding the details of that deployment.
Updated 4 months ago