Datasets
Learn how to upload and edit datasets
Overview
Datasets are the foundational building block for AutoML models. A dataset is the collection of information that will be used for training a custom machine learning model. The AutoML Datasets page offers several convenient features for creating and managing datasets.
Create a Dataset
Create a dataset by navigating to the Datasets page and clicking the Create New Dataset button.
The Create New Dataset button lies at the top right of the Datasets page.
File Upload
The first step of dataset creation is to upload the file(s) containing the relevant data. AutoML supports various structured and unstructured data sources.
Structured data is typically used for creating snapshots and training models. Unstructured data cannot be used for model training but can be used as dataset function input.
View the full list of supported file types in the Dataset Requirements section.
Column Mapping
After uploading your data, if you have provided structured data you will be prompted to confirm the column mapping. In the column mapping step, you can rename columns, ignore unneeded columns, and update the data types of each column.
The column types define how data should be interpreted to display a dataset or train a model. For example, a column containing image URLs should use the Image type, while a column containing raw text data should use the Text type.
Note: column mapping is not applicable for unstructured data—if you upload only unstructured data you will not be prompted to complete column mapping.
View the complete list of column types below.
| Column Type | Description |
|---|---|
| Text | Represents a string of UTF-8 characters. This column type can be used for text to classify, ground truth class labels, and large language model prompts and completions. |
| Image | Represents a URL that points to a publicly accessible image in jpg/jpeg, png, webp, or gif format. This column type can be used as image inputs to image classification or visual moderation models. |
| JSON | Represents a string of structured data in JSON format. |
| Integer | Represents a whole number (no decimal). This column type can be used as ground truth class labels. |
| Float | Represents a decimal number. This column type can be used as ground truth class labels. |
| Boolean | Represents either true or false. This column type can be used as ground truth class labels. |
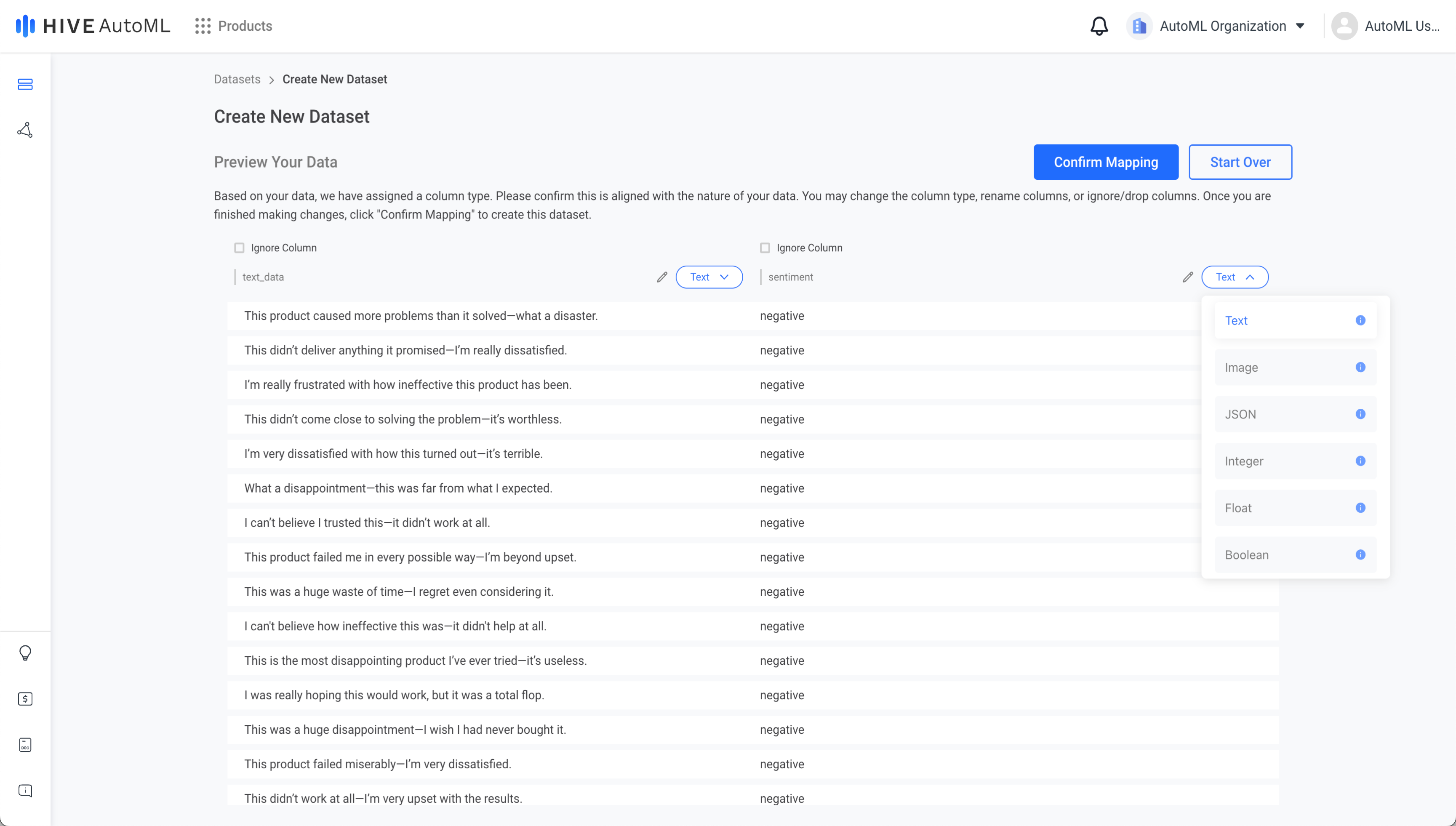
The column type can be selected via a dropdown menu to the right of the column's name.
Preview & Edit a Dataset
After creating a dataset, you can view and edit the data in the dataset’s Live View tab. In the live view, you can update or delete existing rows and add new rows or columns.
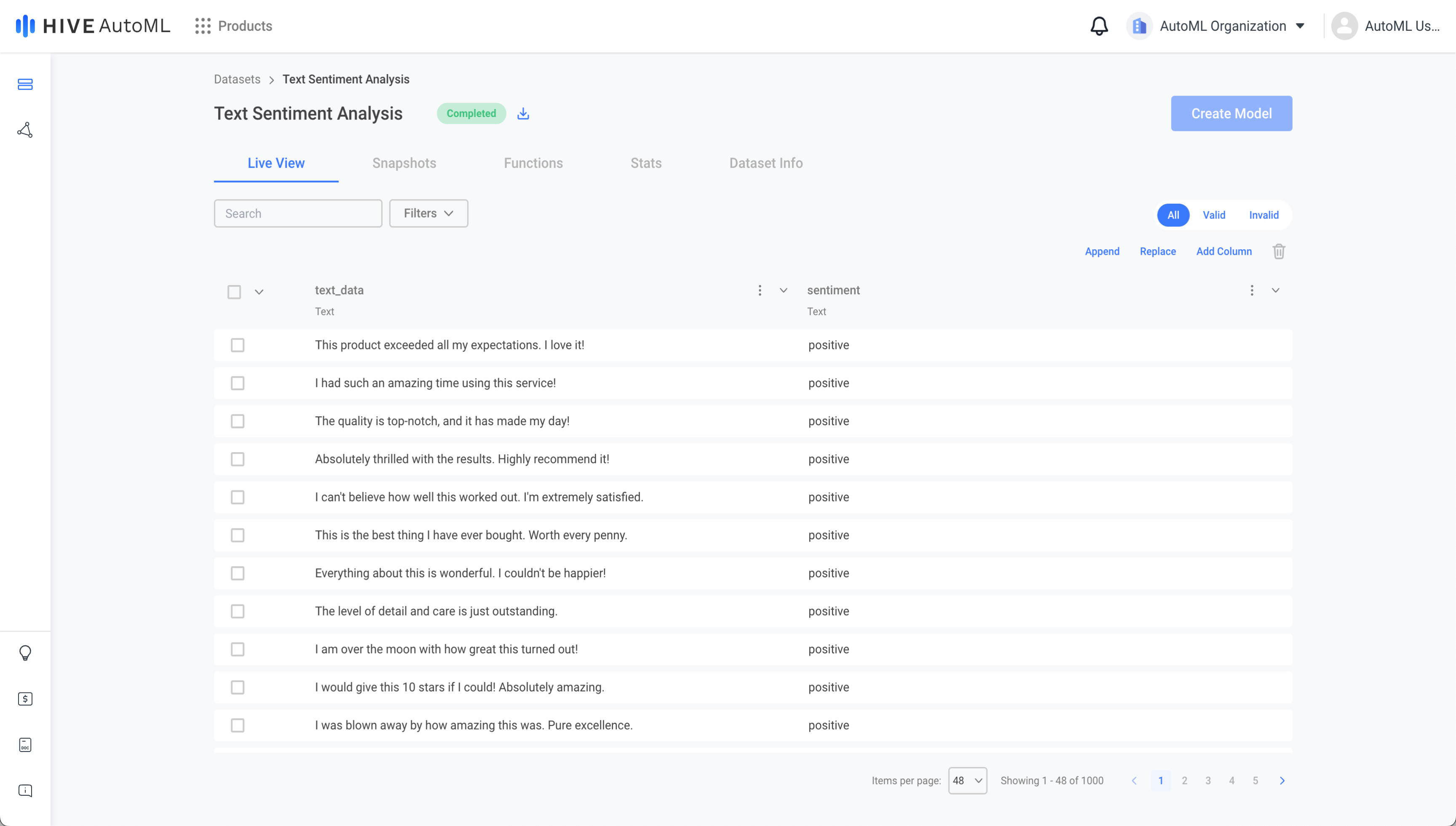
The dataset preview page for a text dataset.
Dataset Requirements
Below are the supported file types for structured and unstructured data.
| Structured Data | Unstructured Data |
|---|---|
| CSV (.csv) | Text (.txt) |
| TSV (.tsv) | Markdown (.md) |
| JSONL (.jsonl) | LaTeX (.tex) |
| Word (.docx) | |
| PDF (.pdf) | |
| RTF (.rtf) |
All datasets must also meet the following requirements.
- UTF-8 encoded
- Composed of 1-20 files
- Max size of 512MB per file
- Max total file size of 5GB
Structured data must also meet the below requirements.
- 1-20 columns
- 1-100,000 rows
- Max 20,000 characters per cell value
Finally, image columns must follow additional requirements.
- Max size of 50MB per image
- Image is supported type (.jpg, .jpeg, .png, .webp, .gif)
Updated 8 months ago