Image Generation APIs
Generate, customize, and scale your image creation with Hive's powerful API platform.
Welcome to our Image Generation API docs!
Our platform enables developers to generate high-quality, customizable images using advanced models like Flux, SDXL, and Hive's fine-tuned enhancements.
This guide covers everything you need to get started with our latest API to build creative applications, enhance your content workflows, and more.
If you'd like to get started right away - head to our Playground and sign up for a (free!) account to test our models.
Why Choose Hive's Image Generation APIs?
- State-of-the-Art Models: Access open-source favorites like Flux and SDXL, plus Hive’s exclusive enhanced versions.
- Customizable Outputs: Generate images tailored to your needs—from photorealistic visuals to unique, branded emojis.
- Easy API Setup: Test on the Playground UI and quickly set up your API with our easy-to-follow docs.
- Protected by Hive Moderation: Moderated by the industry's leading text and visual moderation logic.
Getting Started with Hive
- Explore the Playground: Try out different models, prompts, and settings to see what works best for your use case.
- Choose Your Model:👇
- SDXL: Stability AI's flagship model.
- SDXL Enhanced: Hive's enhanced version of SDXL, served exclusively to our users.
- Flux Schnell: Flux's fastest version of their state-of-the-art image gen suite.
- Flux Schnell Enhanced: Hive's enhanced version that generates photorealistic images with stunning success.
- Emojis: Hive's Emoji model to generate custom, high-quality emojis with transparent backgrounds.
- Integrate the API:
- Our playgrounds include step-by-step integration docs to connect your app or workflow with Hive's APIs and start generating images immediately.
- You can also keep reading below to learn how more!
Key Features of the V3 API:
- Flexible Input Options: Generate images using detailed text prompts with optional negative prompts to exclude unwanted elements.
- Multiple Models: Choose from a lineup of models optimized for speed, photorealism, or artistic expression.
- Content Moderation: Built-in moderation ensures generated content aligns with safety and quality guidelines.
- Customizable Outputs: Control the number of images, output size, and more.

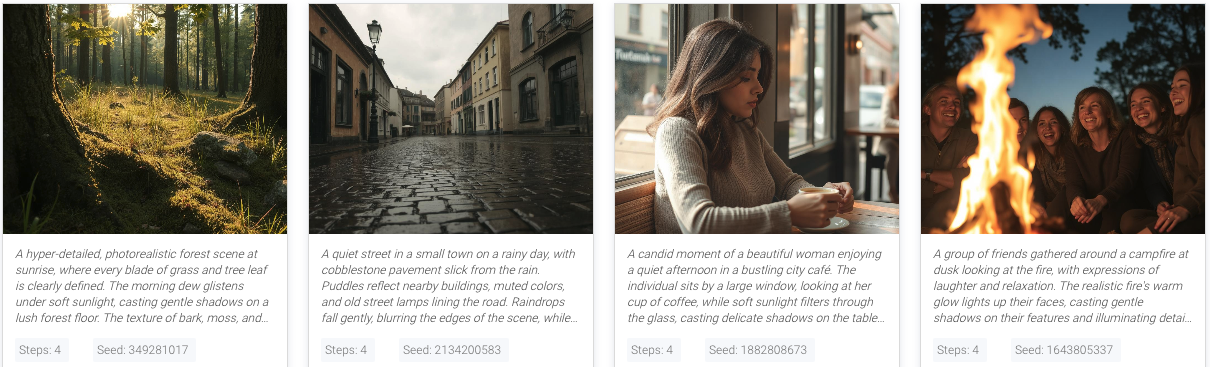
Generating Images
How it Works
The Image Generation APIs enable you to create visuals by sending a text prompt to one of our supported models. The API processes the prompt and returns links to the generated images, along with relevant metadata.
Getting your V3 API Key
Your V3 API Key can be created in the left sidebar of the Hive UI, under "API Keys."
Follow these steps to generate your key:
- Click ‘API Keys’ in the sidebar.
- Click ‘+’ to create a new key scoped to your organization. The same key can be used with any "Playground available" model.
⚠️ Important: Keep your API Key secure. Do not expose it in client-side environments like browsers or mobile apps.
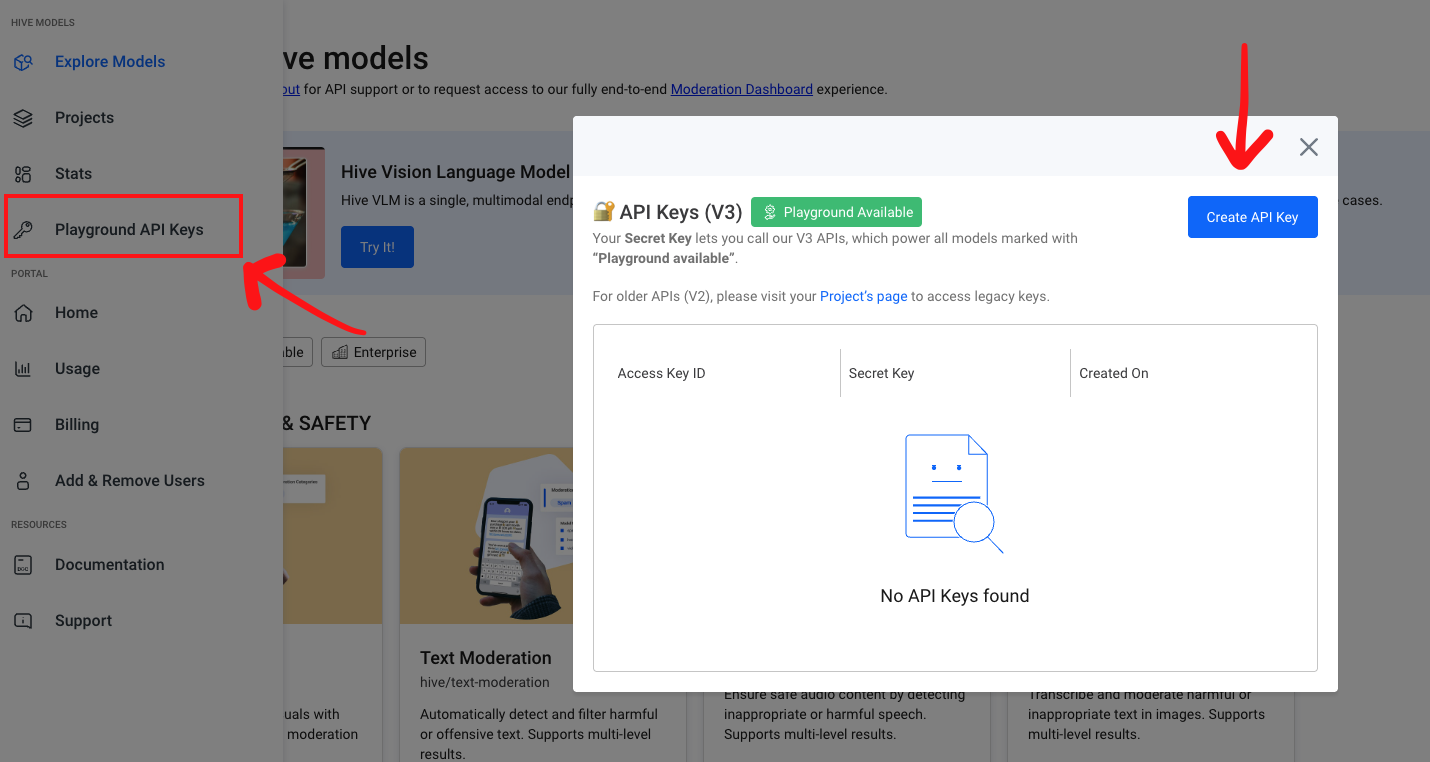
Click '+' to create a new API Key
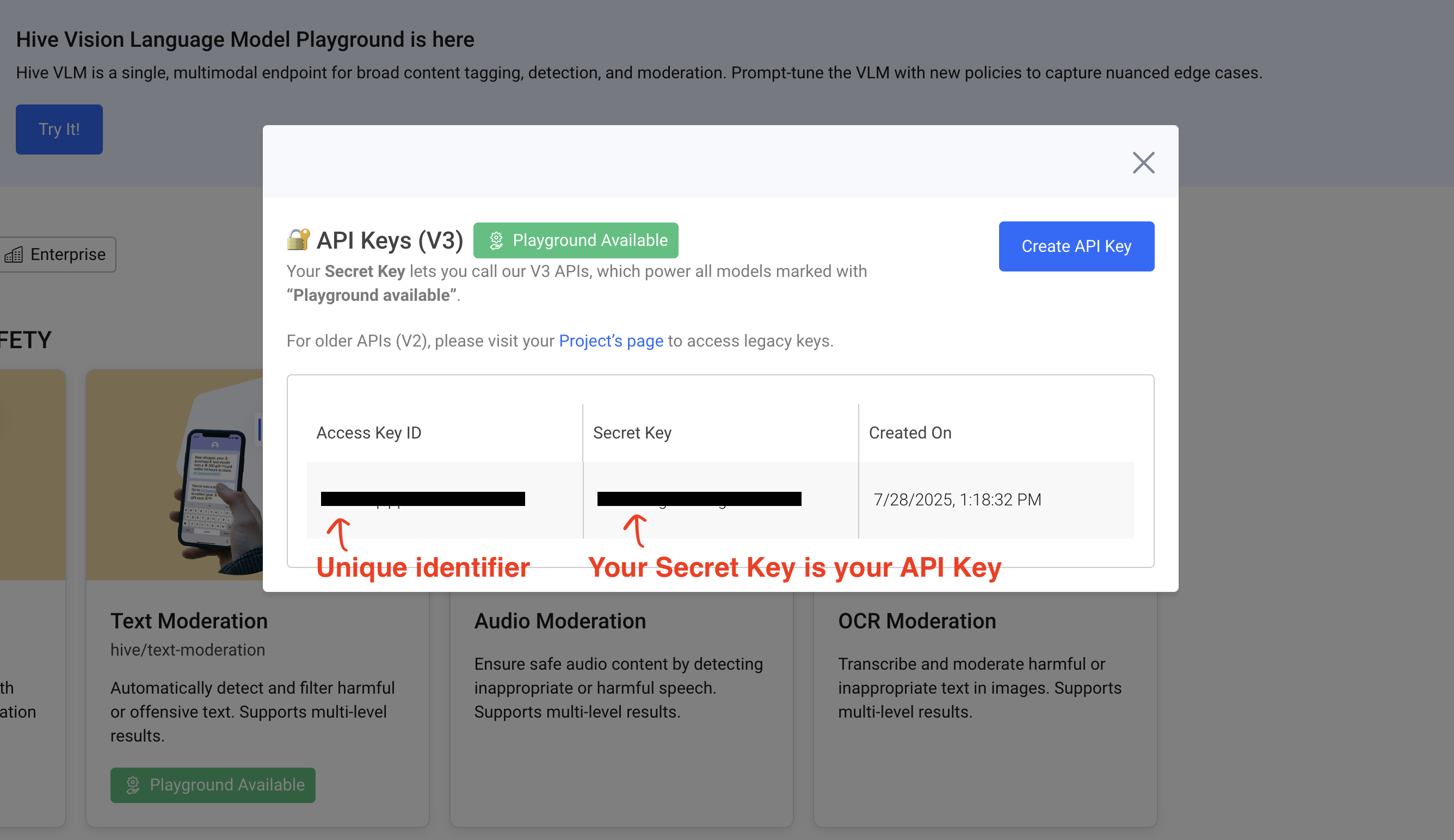
Once you've created an API Key, you can submit API requests using the Secret Key.
Please keep your Secret Key safe.
Request Format
To generate images using the V3 API, you need to send a POST request with a JSON payload that includes details about your prompt and desired output settings.
Here's an example calling the flux-schnell model:
curl 'https://api.thehive.ai/api/v3/black-forest-labs/flux-schnell' \
--header 'authorization: Bearer <API_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"input": {
"prompt": "Nestled within the depths of an enchanted forest, a wooden bridge serves as a pathway lined with glowing lanterns, casting a warm, golden light across its surface. Surrounded by dense trees, the bridge is carpeted with fallen leaves, adding to the mystical ambiance of the setting. The air seems filled with a magical mist, enhancing the dreamlike quality of the forest, inviting onlookers into a tranquil, otherworldly journey.",
"image_size": { "width": 1024, "height": 1024},
"num_inference_steps": 15,
"num_images": 2,
"seed": 123456789,
"output_format": "jpeg",
"output_quality": 90
}
}'Input Parameters
| Field | Type | Description | Required |
|---|---|---|---|
prompt | string | The main text prompt to describe your desired image. | Yes |
num_images | integer | The number of images to generate (1-6). Defaults to 2 images. | No |
image_size | object | Specifies the dimensions of the output image, with width and height in pixels.Defaults to 1024x1024. | No |
num_inference_steps | integer | The number of steps to refine the image during generation. Higher values improve quality but increase processing time. Defaults to 4 steps. | No |
seed | integer | Seed value for deterministic output. Use the same seed to generate consistent results. Defaults to a random integer. | No |
output_format | string | The format of the generated images (jpeg or png).Defaults to png. | No |
output_quality | integer | The quality of the generated images (1-100). Applies only when output_format is jpeg.Default is 80. | No |
Example Response
After a successful request, the API returns a JSON response with details of the generated images and their respective URLs.
{
"id": "<task_id>",
"model": "<model_name>",
"version": "1",
"input": {
"prompt": "Nestled within the depths of an enchanted forest, a wooden bridge serves as a pathway lined with glowing lanterns, casting a warm, golden light across its surface. Surrounded by dense trees, the bridge is carpeted with fallen leaves, adding to the mystical ambiance of the setting. The air seems filled with a magical mist, enhancing the dreamlike quality of the forest, inviting onlookers into a tranquil, otherworldly journey.",
"image_size": { "width": 1024, "height": 1024},
"num_inference_steps": 15,
"num_images": 2,
"seed": 123456789,
"output_format": "jpeg",
"output_quality": 90
},
"output": [
{
"url": "https://cdn.thehive.ai/generated-image1.jpeg"
},
{
"url": "https://cdn.thehive.ai/generated-image2.jpeg"
}
]
}
View and download your images by using output.url.
Our Available Models
We have five different image generation models available, with additional models to be served in the near future.
Here are the differences between our current model offerings:
| Model | Description |
|---|---|
| SDXL (Stable Diffusion XL) | Stability AI's flagship model for artistic image generation, offering versatile and high-quality visuals for creative projects. |
| SDXL Enhanced | Trained by Hive and served exclusively to our customers, this model specializing in portraits, creatures, and landscapes, and delivers a wide range of unique styles for your artistic needs. |
| Flux Schnell | The fastest image generation model from Black Forest Labs, ideal for personal or commercial use. Create stunning visuals with detailed text prompts. |
| Flux Schnell Enhanced | Trained by Hive and served exclusively to our customers, this model elevates Flux's capabilities to deliver high-fidelity, photorealistic images with lifelike quality. Retains Flux base's speed and efficiency, while leading to higher levels of customer satisfaction based on past user studies. |
| Emojis | Create custom, high-quality emojis with transparent backgrounds, perfect for branding, messaging, or creative applications. |
Content Moderation
Hive's powerful content moderation is enabled by default on all of our image generation models. When a request is made to our image generation models, it gets passed through two moderation filters. First, the prompt is run through our text moderation model. If the prompt gets flagged, image generation will not occur. If the prompt does not get flagged, the resulting generated images are run through our visual classification model.
If the image generated does not meet our guidelines for text or visual moderation, the task will not be charged, and the following message will be returned.
{ "return_code": 451, "message": "Images did not pass moderation filters.” }Legacy Support for our Deprecated V2 API
If you’re a legacy user, we’ve included details about our older V2 API. While we recommend upgrading to V3 for the best experience, we’re here to support your existing workflows.
Below are the input fields for an image generation cURL request. The asterisk (*) next to an input field designates that it is required.
text_data*: The text prompt the model uses for image generation.
neg_text: Text prompt where the user can detail aspects that should not be included in the generated image.
num_images: The number of images to generate per request. The default value is 2, with a range of 1 to 6, inclusive.
callback_url: When the task is completed, we will send a callback from our servers to this callback url.
Here is an example of a cURL request using the following format:
curl --location --request POST 'https://api.thehive.ai/api/v2/task/async' \
--header 'authorization: Token <YOUR_TOKEN>' \
--header 'Content-Type: application/json' \
--data-raw '{
"options": {
"neg_text": "grass, pool",
"num_images": 3
},
"text_data": "modern architecture house",
"callback_url": "example_url"
}'V2 Response
After making an image generation model cURL request, you will receive a response consisting of links to the resulting generated images. To see an example API response for this model, you can visit our V2 API reference page.
Hive makes image generation fast, reliable, and customizable.
Let’s get started—sign up here or contact us for any questions!
Updated 8 months ago