Hive Vision Language Model (VLM)
How to integrate with Hive's latest Vision Language Model.
🔑 model key: hive/vision-language-model
What is a Vision Language Model (VLM)?
A VLM is an LLM you prompt that understands images and can return structured answers—so it behaves like a classifier for your custom policy, with lightning-fast responses.
Our Hive Vision Language Model is trained on Hive’s proprietary data, delivering leading performance with the speed and flexibility required for production vision tasks.
- Best-in-class moderation – Flags sexual content, hate, drugs, and other moderation classes.
- Deep multimodal comprehension – Detects fine-grained objects, reads text, and understands spatial and semantic relationships to provide a rich understanding.
- All-in-one task engine – Generate captions, answer questions, run OCR—all through a single endpoint.
What you can send
You can prompt the VLM with your policy and:
- Text only (no image) – e.g., analyze an excerpt against your rules.
- Image only (no text) – e.g., detect content in the image per your policy.
- Text + Image – e.g., marketplace listing: use the photo and the description together.
- NEW! Video only/Text + Video – e.g., label a video frame-by-frame.
- NEW! Multiple images – e.g., detect content in a set of images per your policy.
Tip: Your prompt is your policy. Changing it changes the output. Be specific, include examples, and iterate to match your enforcement needs.
Quickstart: Submit a Prompt + Image
Hive offers an OpenAI-compatible Rest API for querying LLMs and multimodal LLMs. Here are the ways to call it:
- Using the OpenAI SDK
- Directly invoking the REST API
from openai import OpenAI
client = OpenAI(base_url="https://api.thehive.ai/api/v3/", api_key="<YOUR_SECRET_KEY>")
image_response = client.chat.completions.create(
model="hive/vision-language-model",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Describe the scene in one sentence."},
{"type": "image_url",
"image_url": {"url": "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"}}
],
}],
max_tokens=50,
)
print(image_response.choices[0].message.content)import OpenAI from "openai";
const openai = new OpenAI({ baseURL:"https://api.thehive.ai/api/v3/", apiKey:"<YOUR_SECRET_KEY>" });
const completion = await openai.chat.completions.create({
model: "hive/vision-language-model",
messages: [
{ role: "user", content: [
{ type: "text", text: "Describe the scene in one sentence." },
{ type: "image_url", image_url: { url: "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg" } }
] }
],
max_tokens: 50,
});
console.log(completion.choices[0].message.content);curl -X POST https://api.thehive.ai/api/v3/chat/completions \
-H 'Authorization: Bearer <YOUR_SECRET_KEY>' \
-H 'Content-Type: application/json' \
-d '{
"model":"hive/vision-language-model",
"max_tokens":50,
"messages":[
{"role":"user","content":[
{"type":"text","text":"Describe the scene in one sentence."},
{"type":"image_url","image_url":{"url":"https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"}}
]}
]
}'Try our Playground UI if you'd like to start testing the VLM right away!
NOTE! For our Virginia (VA1) customers, please use the URL: https://api-va1.thehive.ai/api/v3/
Quickstart: Submit a Prompt + Video
from openai import OpenAI
client = OpenAI(base_url="https://api.thehive.ai/api/v3/", api_key="<YOUR_SECRET_KEY>")
video_response = client.chat.completions.create(
model="hive/vision-language-model",
messages=[{
"role":"user",
"content":[
{
"type":"media_url",
"media_url":{
"url":"https://example-videos/video.mp4",
"sampling": { "strategy": "fps", "fps": 1 }, # Sample 1 frame per second, and run the model on each sampled frame. Default 1 fps.
"prompt_scope":"per_frame" # vs. "once"
}
},
{ "type":"text", "text":"Detect objects and summarize key events." }
]
}]
)
for i, choice in enumerate(video_response.choices):
print(f"Frame {i}: {choice.message.content}")Create your V3 API Key
- In the left sidebar click Playground API Keys, or open this link.
- Copy the Secret Key and use it when sending API requests.
⚠️ Keep your Secret Key safe—do not share or embed it client-side.
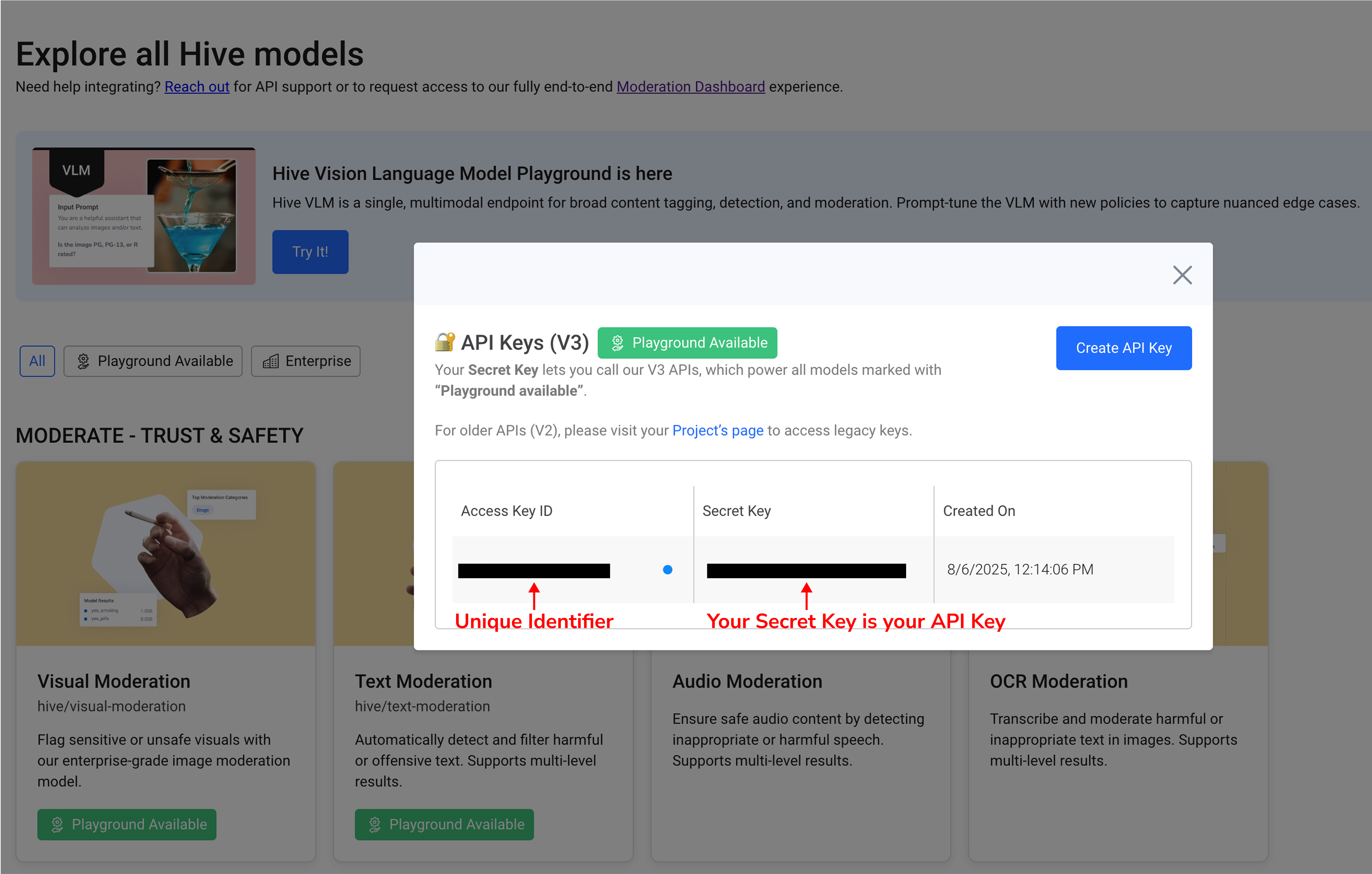
Create your V3 API Key: https://thehive.ai/explore?api_keys=1
Please keep your Secret Key safe.
Performance Tips
Minimizing Latency and Usage Volume
Hive VLM tokenizes each frame into square "patches."
Images small enough to fit into a single patch (square images ≤ 633x633) use only 256 input tokens.
Larger images are split into up to 6 patches (max 1,536 tokens) which increases latency and usage volume.
For the fastest response, resize or center-crop your images to ≤ 633x633 before calling the API.
Video Sampling & Usage Volume
- Fewer frames → lower latency & usage volume. Start with higher
strideor lowerfpsvalues for summaries. - The model processes each sampled frame like an image, and total tokens scale with frames × image tokens (see Image tokenization in Tokenization).
Maximizing OCR Accuracy
For OCR tasks, it is recommended to keep your image patch size higher.
The higher the patch size (up to 6), the more accurate the VLM performs on text-on-image tasks.
Context Window
Hive VLM's context window is ~65k input tokens.
Bias Tuning
Bias tuning allows you to weight certain classes more in the VLM than others. If you increase a class weight, the class is more likely to be returned. This will increase recall and lower precision. Essentially, this allow you to choose different points in the PR-curve while still using an LLM style model.
The way you can configure is to add the following JSON anywhere in the prompt:
{"biases":{"<task_name>":{"<class_name>":[10,-10]}}}Below is an example:
Task: animal
Is there an animal in this picture?
### yes
The image contains one or more animals that exist in the real world, including but not limited to:
* One or more real-world animals are depicted in the image
* Includes living creatures like dogs, cows, birds, or recognizable species
* Features anatomically plausible animals with realistic anatomy and traits
### no
The image contains no real-world animals, including but not limited to:
* Image consists solely of humans, fantasy characters, or lifeless things
* Stylized or fictional designs that do not mimic real animals
* Contains no depiction of any known or actual animal species
{biases: {animal: {yes: 1}}}
This will make the prompt more likely to return "yes" for the animal task. For this example, increasing the weight of "yes" will increase recall and lower precision of the model on the animal task.
Other ways to call the Hive VLM API
Sending a Prompt + Image Base64
Just swap the value inside "url" to be your encoded base64 string; everything else is identical.
{"type":"image_url","image_url":{"url":"data:image/jpeg;base64,<BASE64_DATA>"}}Sending with a JSON Schema
When you need the model to return structured JSON, define a JSON schema that the model should conform to.
from openai import OpenAI
client = OpenAI(base_url="https://api.thehive.ai/api/v3/", api_key="<YOUR_SECRET_KEY>")
json_schema = {
"name": "subject_classification",
"schema": {
"type": "object",
"properties": {"subject": {"type": "string", "enum": ["person", "animal", "vehicle", "food", "scenery"]}},
"required": ["subject"], "additionalProperties": False
}
}
completion = client.chat.completions.create(
model="hive/vision-language-model",
messages=[{"role": "user", "content": [
{"type": "text", "text": "Classify the main subject (person, animal, vehicle, food, scenery). Return JSON only."},
{"type": "image_url", "image_url": {"url": "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"}}
]}],
response_format={"type": "json_schema", "json_schema": json_schema},
max_tokens=50,
)
print(completion.choices[0].message.content)from openai import OpenAI
# ── Client setup ────────────────────────────────────────────────────────────────
client = OpenAI(
base_url="https://api.thehive.ai/api/v3/", # Hive's endpoint
api_key="<YOUR_SECRET_KEY>" # Replace with your API key
)
const jsonSchema = {
name: "subject_classification",
schema: {
type: "object",
properties: { subject: { type: "string", enum: ["person", "animal", "vehicle", "food", "scenery"] } },
required: ["subject"], additionalProperties: false
}
};
const completion = await openai.chat.completions.create({
model: "hive/vision-language-model",
messages: [{
role: "user",
content: [
{ type: "text", text: "Classify the main subject (person, animal, vehicle, food, scenery). Return JSON only." },
{ type: "image_url", image_url: { url: "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg" } }
]
}],
response_format: { type: "json_schema", json_schema: jsonSchema },
max_tokens: 50,
});
console.log(JSON.parse(completion.choices[0].message.content).subject);curl -X POST https://api.thehive.ai/api/v3/chat/completions \
-H 'Authorization: Bearer <YOUR_SECRET_KEY>' \
-H 'Content-Type: application/json' \
-d '{
"model":"hive/vision-language-model",
"max_tokens":50,
"response_format":{
"type":"json_schema",
"json_schema":{
"schema":{
"type":"object",
"properties":{"subject":{"type":"string","enum":["person","animal","vehicle","food","scenery"]}},
"required":["subject"],
"additionalProperties":false
},
"strict":true
}
},
"messages":[
{"role":"user","content":[
{"type":"text","text":"Classify the main subject (person, animal, vehicle, food, scenery). Return JSON only."},
{"type":"image_url","image_url":{"url":"https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"}}
]}
]
}'
Request Format
Supported Media Types
Image:
.jpg,.png,.webp,.gifVideo:
.mp4,.webm,.m4vSize Limits:
URL/Multipart Upload: Images: 200MB, Videos: 15GB
Base64: 20MBVideo Length Limits:
URL/Base64: 180 seconds
Note: It is possible to hit the input token limit (16,384 (for SF1) or 65,536 (for VA1)) before hitting the video length limit.
Parameter Reference
| Field | Type | Definition |
|---|---|---|
| messages | array of objects |
|
| model | string | Required. The name of the model to call. |
| role | string | The role of the participant in the conversation. Must be user or assistant. |
| content | string OR array of objects | Your content string. If array, each object must have a type and corresponding data, as shown in the examples above. content[].type can be image_url, media_url, or video_url. |
| text | string | Referenced inside content arrays, containing the text message to be sent. |
| image_url / media_url / video_url | object | Contains the media URL or Base64-encoded string, inside the subfield url. |
| response_format | object | response_format constrains the model response to follow the JSON Schema you define. This setting is very useful if you'd like Hive VLM to follow a specified set of tasks, defined in a JSON.
|
| max_tokens | int | Output token cap. Default 512 (1 – 2048). |
| temperature | float | Controls randomness (0 = deterministic). Default 0 (0 - 1). |
| top_p | float | Nucleus sampling cutoff: sample only from the smallest set of tokens whose cumulative probability ≥ top_p. Default 0.1 (0-1].
|
| top_k | int | Limits sampling to top K tokens. Default 1 (0-1). |
Video-only parameters
| Field | Type | Required | Definition |
|---|---|---|---|
content[].media_url.sampling.strategy | string | Optional, Default = "fps" = 1 |
|
content[].media_url.sampling.stride | integer | Optional, used with strategy = "stride". Default = 1 | Analyze every Nth frame (e.g., 5 = every 5th frame). |
content[].media_url.sampling.fps | number | Optional, used with strategy = fps. Default = 1 | Analyze N frames per second (e.g., 1 = 1 fps). |
content[].media_url.prompt_scope | string | Optional, Default = "once" | Prompt scope defines how the prompt is applied to sampled video frames.
|
Response Format
After making a request, you’ll receive a JSON response with the model's output text. Here’s a sample output:
{
"id": "1234567890-abcdefg",
"object": "chat.completion",
"model": "hive/vision-language-model",
"created": 1749840139221,
"choices": [
{
"index": 0, # Videos with prompt_scope = per_frame will return multiple indices.
"message": {
"role": "assistant",
"content": "{ \"subject\": \"scenery\" }"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1818,
"completion_tokens": 11,
"total_tokens": 1829
}
}Note: If you provide a JSON schema, the API still returns a string, which can be parsed into JSON.
Parameter Reference
| Field | Type | Definition |
|---|---|---|
| id | string | The Task ID of the submitted task. |
| model | string | The name of the model used. |
| created | int | The timestamp (in epoch milliseconds) when the task was created. |
| choices | array of objects | Contains the model’s responses. Each object includes the index, message, and finish_reason. |
| usage | object | Token counts for prompt, completion, and total. |
Those are the only fields you need for most integrations. Everything else remains identical across URL, Base64, and schema variants.
Common Errors
The VLM has a default starting rate limit of 5 requests per second. You may see this error below if you submit higher than the rate limit.
To request a higher rate limit please contact us!
{
"status_code": 429,
"message": "Too Many Requests"
}A positive Organization Credit balance is required to continue using Hive Models. Once you run out of credits requests will fail with the following error.
{
"status_code":405,
"message":"Your Organization is currently paused. Please check your account balance, our terms and conditions, or contact [email protected] for more information."
}Tokenization
Hive VLM usage is measured by input + output tokens. Latency scales with tokens too, so smaller inputs → fewer tokens → faster responses.
Images: how tokenization works
For each frame, we:
- Start with the image’s aspect ratio and area.
- Example: a 1,024 × 1,024 picture has ratio = 1.0 and area = 1M px.
- Consider square tiles (“patches”) that cover the image (from 1 up to 6 tiles).
- A “tile” is a square crop that the model turns into a fixed 256-token chunk.
- We allow from 1 tile up to 6 tiles in total.
So the grids considered are 1 × 1, 1 × 2, 2 × 1, 2 × 2, 1 × 3, 3 × 1 …
- Pick the grid that best matches the image aspect ratio; if tied, pick the one with more tiles.
- e.g., a 3 × 2 grid (ratio = 1.5) fits an 800 × 600 image (ratio ≈ 1.33) better than a 2 × 2 grid (ratio = 1.0).
- Compute 256 tokens per tile:
tokens_per_frame = (num_tiles x 256) + 2 - Finally, add 258 more tokens to images with greater than 1 patch.
| Image resolution | Chosen grid | Tiles | Tokens |
|---|---|---|---|
| 1x1 | 1 | Only 258 + 2 tokens |
| 633x528 or 528x633 (5:6 or 6:5 aspect ratio, fastest latency) | 1x1 | 1 | Only 258 + 2 tokens |
| 1024x1024 | 2x2 | 4 | (4x256) + 2 + 258 = 1284 tokens |
| 800x600 | 3x2 | 6 | (6x256) + 2 + 258 = 1796 tokens |
Videos
A video request becomes sampled frames → each frame is tokenized like an image → tokens are summed.
What gets summed depends on:
- Sampling (how many frames)
- Your prompt scope.
"per_frame"→ apply prompt to each sampled frame; multiple outputs (one per frame). Any text input tokens you provide in the request will be counted again for every frame, and total output tokens will be the sum of all individual outputs."once"→ apply prompt once across all frames; single output. Your input tokens will still sum the frames you included in your sampling strategy.
Lower FPS / higher stride → fewer frames → fewer tokens.
| Video Length | Sampling | Frames | Frame dimensions | Tokens / frame | Image tokens only |
|---|---|---|---|---|---|
| 10s | fps: 1 | 10 | 633x633 → 1 tile | 260 | 2,600 |
| 10s | fps: 2 | 20 | 633x633 → 1 tile | 260 | 5,200 |
Updated 2 months ago