Snapshots
A quick guide to creating and using snapshots
Overview
A snapshot is an immutable point-in-time version of a dataset that is used to train an AutoML model. Multiple snapshots can be created from the same dataset and multiple models can be trained from the same snapshot.
Create a Snapshot
Create a snapshot by navigating to a dataset’s Snapshots tab and clicking the Create Snapshot button. The snapshot creation form requires a snapshot type, an input column, and one or more label columns. Additionally, there are optional snapshot split and filtering inputs.
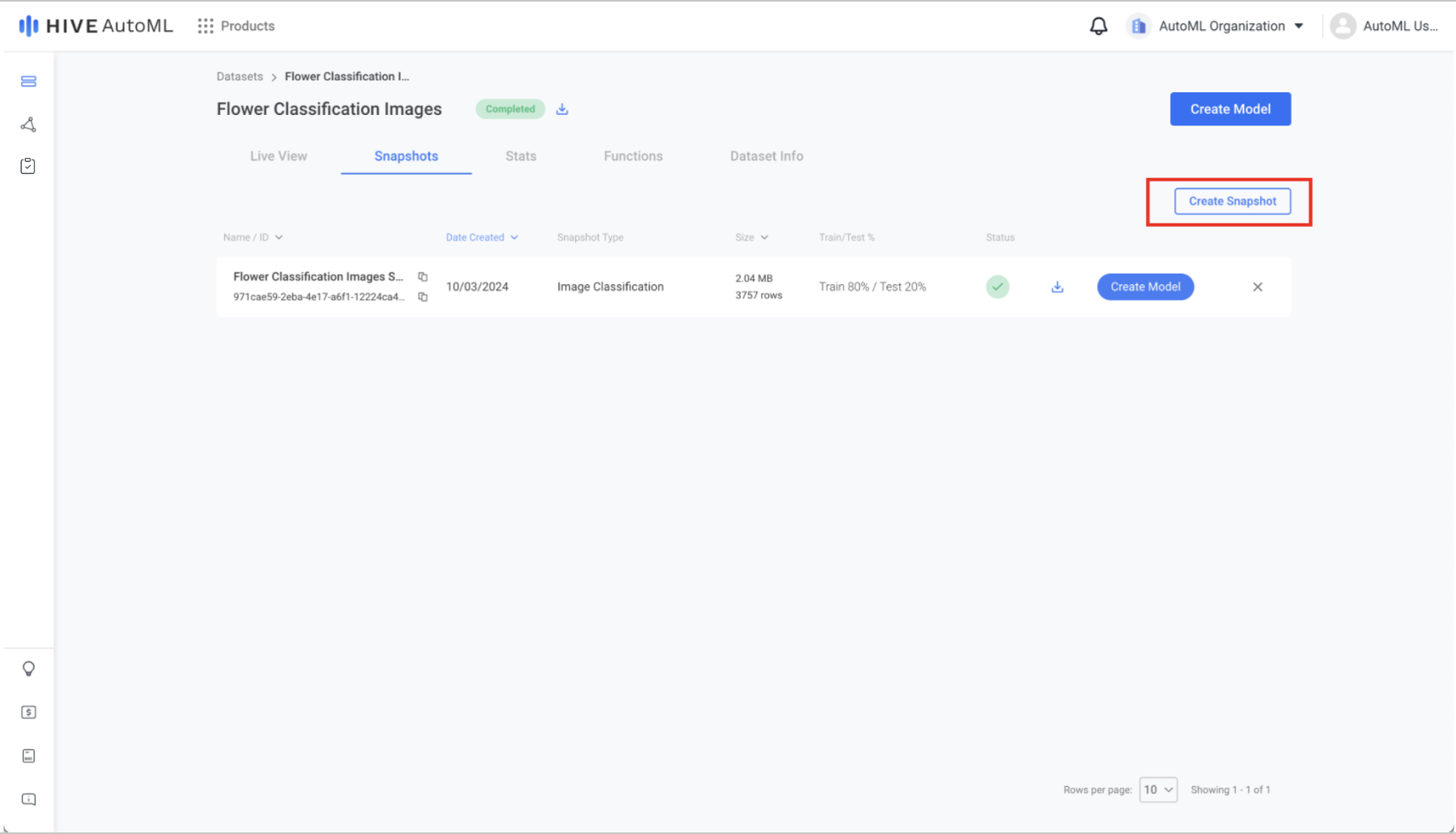
The Create Snapshot button lies at the top right of a dataset's Snapshots tab.
For more information on snapshot creation and snapshot types, see the Snapshot Requirements section below.
Snapshot Requirements
| Snapshot Type | Description | Supported Models |
|---|---|---|
| Text Classification | Snapshot that can be used to train any text classification model. |
|
| Image Classification | Snapshot that can be used to train any image classification model. |
|
| Vision Language Model | Snapshot used to evaluate the Vision Language Model across video, image and text data. |
|
| Backup | Snapshot that can be used to restore a dataset but NOT to train a model. | -- |
Text Classification
| Column | Description | Requirements | Example |
|---|---|---|---|
| Text Input* | Text data that will be classified by the model using the Labels column | 1. Must be Text column type | “The movie was one of the best I’ve seen in the past year, hands down.” |
| Labels* | Class labels that the model will assign to text inputs | 1. Must have between 2 and 20 unique values 2. Max 512 tokens per row | “positive” |
Image Classification
| Field | Description | Requirements | Example |
|---|---|---|---|
| Image Input* | Images that will be classified by the model using the Labels column | 1. Must be Image column type | https://www.link-to-example-images.com/my_dog |
| Labels* | Class labels that the model will assign to image inputs | 1. Must have between 2 and 20 unique values 2. Max 512 tokens per row | "dog" |
Backup
There are no validations or requirements for backup snapshots.
Updated 9 months ago