LLM APIs - Documentation
Integrate with Llama models or use Hive's custom-trained LLM, tailored for flexible moderation tasks.
Deprecated as of July 1st, 2025
This documentation refers to our LLMs, which are no longer maintained and have been turned off since July 1st, 2025.
New integrations should use our newly improved Hive VLM.
These pages remain accessible for archival reference only.
Welcome to our LLM API docs!
Developers can easily integrate with Llama 3.1 and 3.2 models at multiple sizes using our platform.
You can also try out Hive's LLM, called Moderation 11b Vision Language Model - which has been purpose-built for specialized tasks like moderation and policy-following.
If you'd like to get started right away - head to our Playground and sign up for a (free!) account to test our models.
Models
We offer a variety of Meta’s open-source Llama Instruct models from the 3.1 and 3.2 series, with additional models to be served in the near future.
Here are the differences between our current LLM offerings:
| Model | Description |
|---|---|
| Llama 3.2 1B Instruct | Llama 3.2 1B Instruct is a lightweight, multilingual, text-only model that fits onto both edge and mobile devices. Use cases where the model excels include summarizing or rewriting inputs, as well as instruction following. Try out the Playground for this model here ! |
| Llama 3.2 3B Instruct | A versatile, high-performance model optimized for lightweight language processing across diverse applications. Try out the Playground for this model here ! |
| Llama 3.1 8B Instruct | Llama 3.1 8B Instruct is a more advanced multilingual model designed for complex integrations, offering exceptional language understanding and accuracy. Try out the Playground for this model here ! |
| Llama 3.1 70B Instruct | A high-powered multilingual model built for large-scale applications, delivering superior performance for intricate tasks and workflows. Compared to other available open source and closed chat models, Llama 3.1 70B Instruct achieves higher scores across common industry benchmarks. Try out the Playground for this model here ! |
| Hive Moderation 11B Vision Language Model | An vision-enhanced LLM (i.e. VLM) that also excels at handling text-based moderation tasks and use cases. Try it out here! |
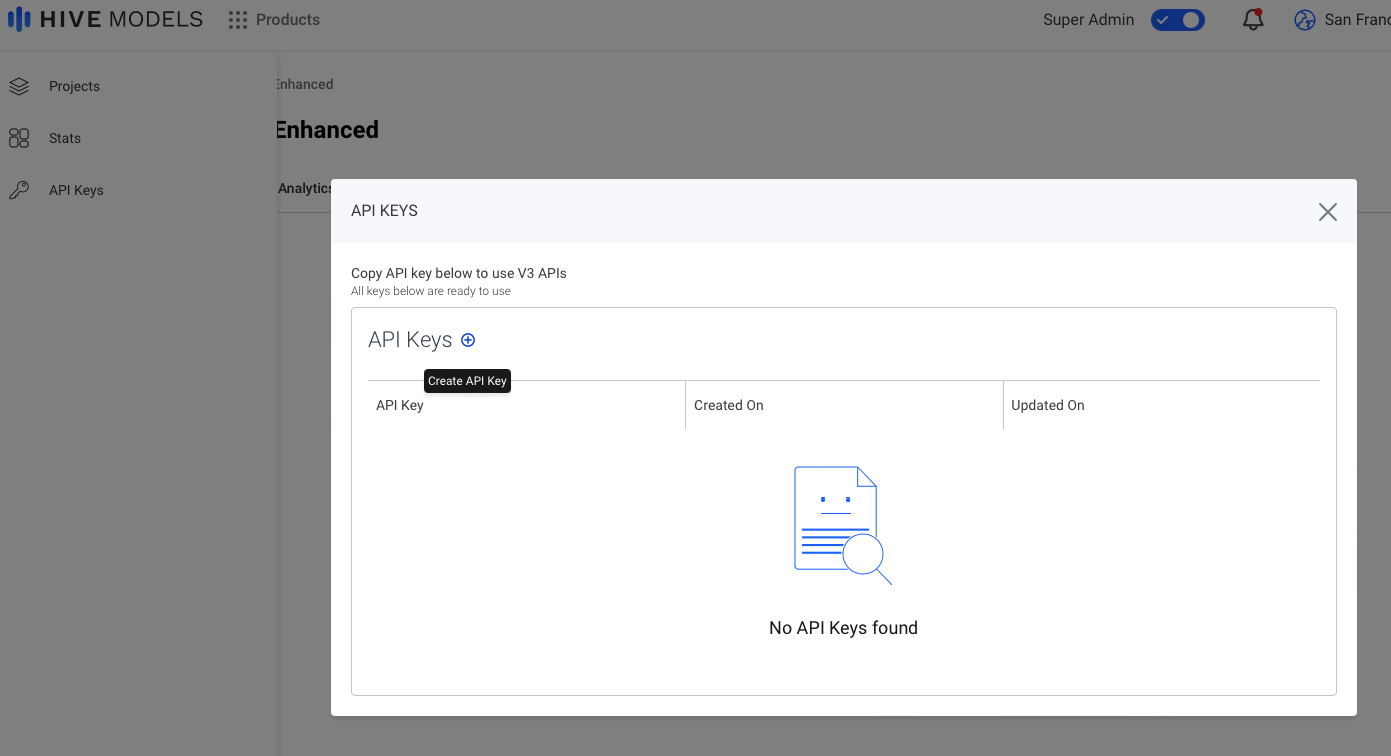
Getting your V3 API Key
Your V3 API Key can be created in the left sidebar of the Hive UI, under "API Keys."
Follow these steps to generate your key:
- Click ‘API Keys’ in the sidebar.
- Click ‘+’ to create a new key scoped to your organization. The same key can be used with any "Playground available" model.
⚠️ Important: Keep your API Key secure. Do not expose it in client-side environments like browsers or mobile apps.
V3 Request Format
Below are the input fields for a multimodal LLM cURL request. The asterisk (*) next to an input field designates that it is required.
model*: The name of the model to call.
max_tokens: Limits the number of tokens in the output. Default: 2048. Range: 1 to 2048.
messages*: A structured array containing the conversation history. Each object includes a role and content.
role: The role of the participant in the conversation. Must be system, user, or assistant.
content: Your content string, which can be a string or an array of objects. If it's an array, each object must have a type and corresponding data, as shown in the example below.
text: Referenced inside content arrays, containing the text message to be sent.
Here is an example of a cURL request using the following format:
curl --location --request POST 'https://api.thehive.ai/api/v3/chat/completions' \
--header 'authorization: Bearer <API_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"model": "meta-llama/llama-3.2-1b-instruct",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "Explain the concept of reinforcement learning."
}
]
}'
Response
To see example API responses for these models, you can visit their respective API playgrounds, which contain additional documentation.
LEGACY -- V2 Request Format
Below are the input fields for an LLM cURL request. The asterisk (*) next to an input field designates that it is required.
| Input Field | Type | Definition |
|---|---|---|
| text_data* | string | The main text prompt. This describes what the text response should include. |
| callback_url* | string | When the task is completed, we will send a callback from our servers to this callback url. |
| system_prompt | string | String that provides context for how the model should respond to all requests. |
| prompt_history | Provides the chat history in chronological order, where the last item is the most recent chat. Each item needs to be a dictionary with the keys "content" and "role". | |
| top_p | float | A value between 0 and 1. If the value is 0, requests should be more diverse than when set to a higher value. |
| temperature | float | A value between 0 and 1. If this value is 0, a repeated request should yield the same response. If this value is 1, a repeated request should yield different responses. |
| max_tokens | int | This is the maximum token window that you want for your model completion output. |
Here is an example of a cURL request using the following format:
curl --location 'https://api.thehive.ai/api/v2/task/async' \
--header 'Authorization: Token <YOUR_API_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"text_data": "<YOUR_PROMPT>",
"callback_url": "<YOUR_CALLBACK_URL>",
"options": {
"system_prompt": "<YOUR_SYSTEM_PROMPT>",
"prompt_history": "<YOUR_PROMPT_HISTORY>",
"top_p": <YOUR_TOP_P>,
"temperature": <YOUR_TEMPERATURE>,
"max_tokens": <YOUR_MAX_TOKENS>
}
}'
Response
After making an LLM cURL request, you will receive a text response. To see another example API request and response for this model, along with detailed information about the parameters, you can visit our API reference page.
Updated about 1 month ago