VLM APIs - Documentation
A guide on how to integrate with our multimodal LLMs to process images and generate text
Deprecated as of July 1st, 2025This documentation refers to our legacy vision language models, which are no longer maintained and have been turned off since July 1st, 2025.
New integrations should use our newly improved Hive VLM.
These pages remain accessible for archival reference only.
Overview
Our cutting-edge multimodal LLMs (large language models) leverage both powerful text and image reasoning capabilities simultaneously. Multimodality refers to a model's ability to concurrently process inputs across multiple modalities (e.g. images and text).
With their multimodal capabilities, these models can tackle a wide range of complex use cases—ranging from image captioning with our Llama 3.2 11B Vision Instruct to expanding moderation workflows with our proprietary Hive Moderation 11B Vision Language Model.
Models
Apart from our proprietary models, we also offer some of Meta’s open-source Llama Vision Instruct models from the 3.2 series.
Below are our current multimodal LLM offerings, with additional models to be served in the near future:
| Model | Description |
|---|---|
| Llama 3.2 11B Vision Instruct | Llama 3.2 11B Vision Instruct is an instruction-tuned model optimized for a variety of vision-based use cases. These include but are not limited to: visual recognition, image reasoning and captioning, and answering questions about images. Try out the Playground for this modelhere! |
| Hive Moderation 11B Vision Language Model (VLM) | Moderation 11B Vision Language Model is built on Llama 3.2 11B Vision Instruct and enhanced with Hive's proprietary data, expanding the capabilities of our established moderation suite. Designed to handle complex contexts and edge cases, this model combines state-of-the-art multimodal understanding with specialized moderation expertise, making it ideal for identifying and addressing nuanced content across text and images. Try out the Playground for this modelhere! |
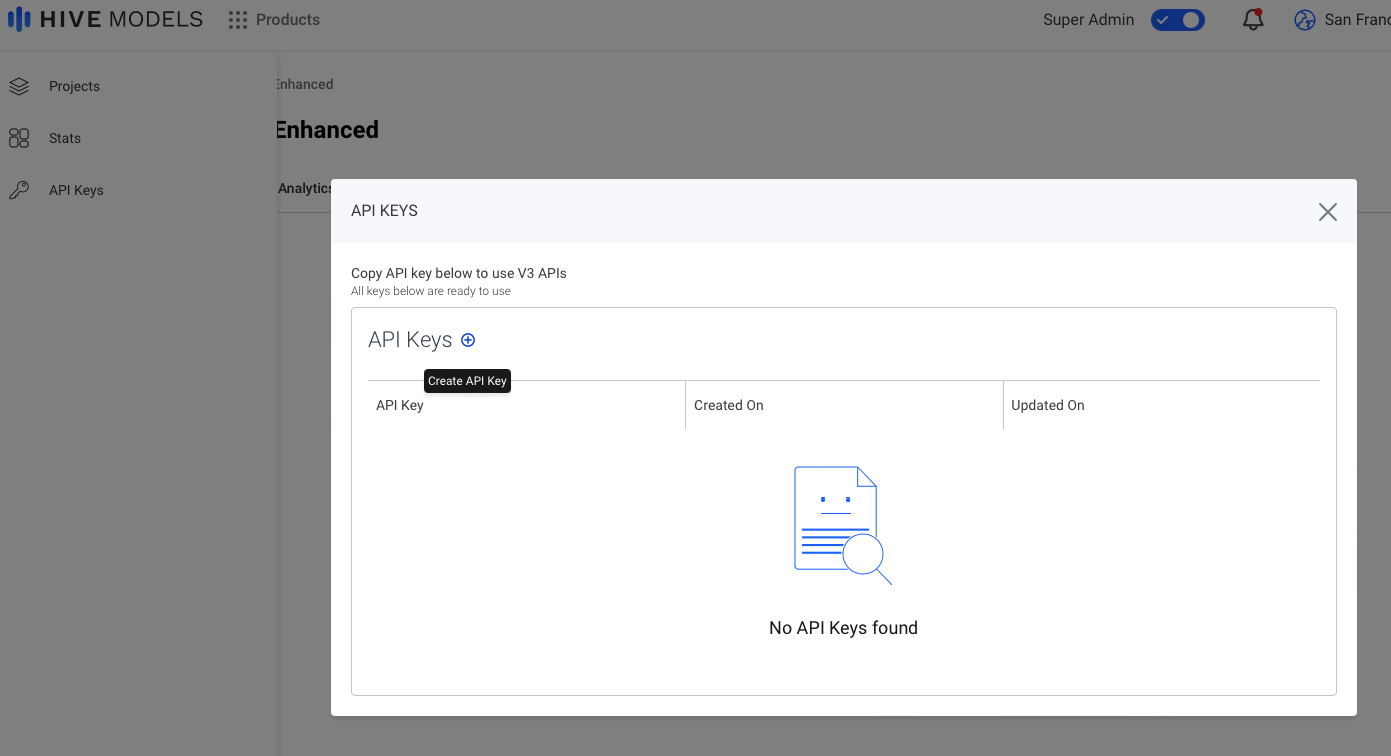
Getting your V3 API Key
Your V3 API Key can be created in the left sidebar of the Hive UI, under "API Keys."
Follow these steps to generate your key:
- Click ‘API Keys’ in the sidebar.
- Click ‘+’ to create a new key scoped to your organization. The same key can be used with any "Playground available" model.
⚠️ Important: Keep your API Key secure. Do not expose it in client-side environments like browsers or mobile apps.
Request Format
Below are the input fields for a multimodal LLM cURL request.
The asterisk (*) next to an input field designates that it is required.
model: The name of the model to call.
max_tokens: Limits the number of tokens in the output. Default: 2048. Range: 1 to 2048.
messages: A structured array containing the conversation history. Each object includes a role and content.
role: The role of the participant in the conversation. Must be system, user, or assistant.
content: Your content string, which can be a string or an array of objects. If it's an array, each object must have a type and corresponding data, as shown in the example below.
text: Referenced inside content arrays, containing the text message to be sent.
image_url: Contains the image URL or Base64-encoded string, inside the subfield url.
Example 1: Sending an Image via Image URL:
curl --location --request POST 'https://api.thehive.ai/api/v3/chat/completions' \
--header 'authorization: Bearer <API_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"model": "hive/moderation-11b-vision-language-model",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you describe what is in this photo?"
},
{
"type": "image_url",
"image_url": {
"url": "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"
}
}
]
}
]
}'Example 2: Sending an Image via Base64 Encoding:
First, convert your image to Base64. You can do this in Python:
import base64
with open("image.jpg", "rb") as image_file:
base64_string = base64.b64encode(image_file.read()).decode("utf-8")
print(base64_string) # Use base64_string in the API request
curl --location --request POST 'https://api.thehive.ai/api/v3/chat/completions' \
--header 'authorization: Bearer <API_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"model": "hive/moderation-11b-vision-language-model",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you describe what is in this photo?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,{base64_string}"
}
}
]
}
]
}'
Why Use Base64?
- Avoids the need to host images online.
- Useful for secure environments where direct URLs are restricted.
Deprecated Request Format
This format cannot be used with the Hive Moderation 11B VLM.
Below are the input fields for a cURL request using a deprecated version of Llama 3.2 11B Vision Instruct, which is used for legacy Image Captioning workflows.
The asterisk (*) next to an input field designates that it is required.
media*: The path to your input image or video.
question: An optional field to ask a question about the input image or video.
Here is an example of a cURL request using the following format:
curl --location 'https://api.thehive.ai/api/v1/task/async' \
--header 'Authorization: Token <YOUR_TOKEN>' \
--form 'url=<YOUR_URL>' \
--form 'options="{\"question\":\"<YOUR_QUESTION_HERE>\"}"'Response
To see example API responses for these models, you can visit their respective API playgrounds, which contain additional documentation.
To see an example API response for the deprecated request format, you can visit the following API reference page.