Hive Vision Language Model (VLM)
hive/vision-language-model
About
🔑 model key: hive/vision-language-model
The Hive Vision Language Model is trained with Hive's proprietary data, delivering industry-leading content moderation while retaining the generalization and speed you need for everyday vision tasks.
- Best-in-class moderation - reliably detects sexual and explicit content, abuse, hate, drugs, even in edge-case and nuanced scenarios across text and images.
- General capability - the same model powers captioning, visual Q&A, and OCR comparably to other options, eliminating the need to switch models.
- Proven at scale - already processing billions of images monthly with high accuracy.
How to Get Started
Authentication is required to use these models. You’ll need an API Key, which can be created in the left sidebar.
Follow these steps to generate your key:
- Click ‘API Keys’ in the sidebar.
- Click ‘+’ to create a new key scoped to your organization. The same key can be used with any "Playground available" model.
⚠️ Important: Keep your API Key secure. Do not expose it in client-side environments like browsers or mobile apps.
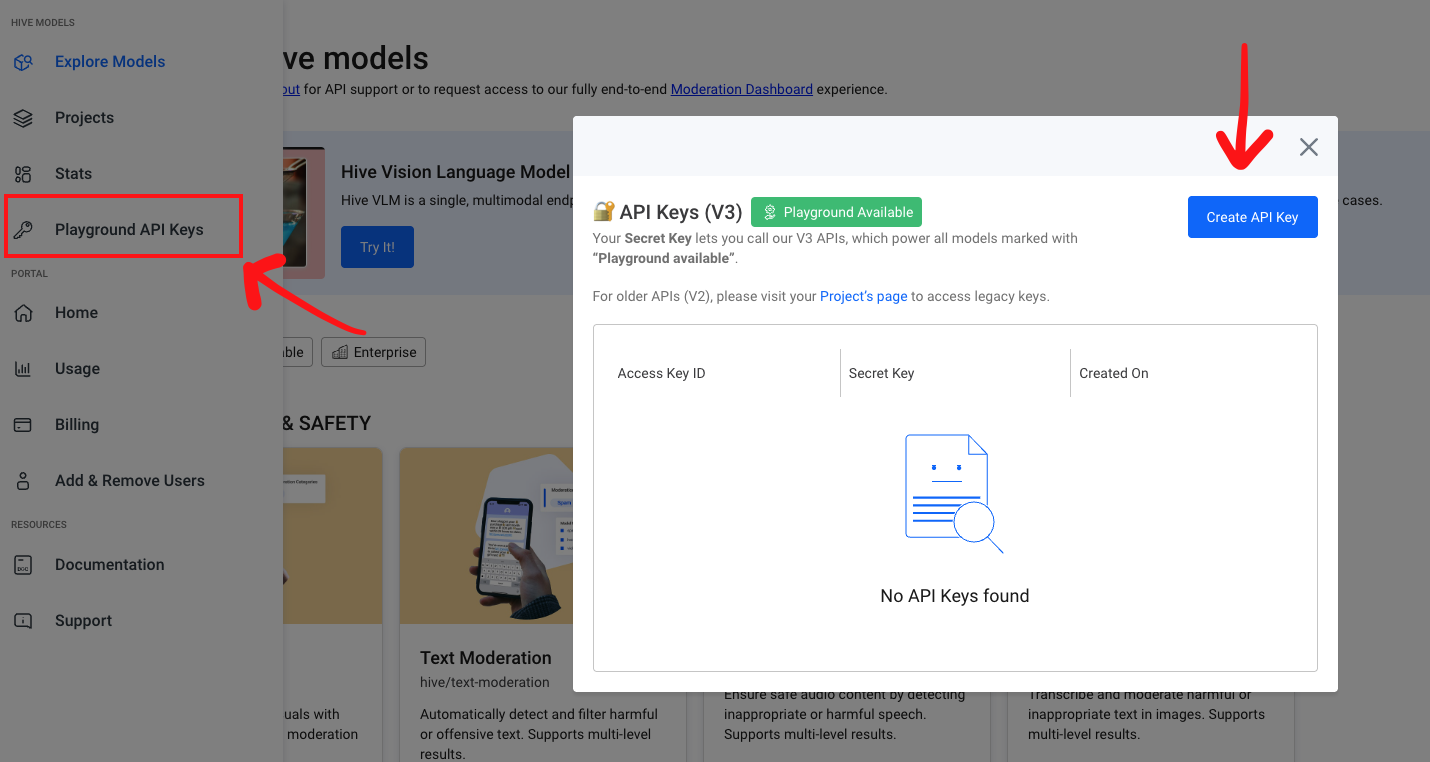
Click '+' to create a new API Key
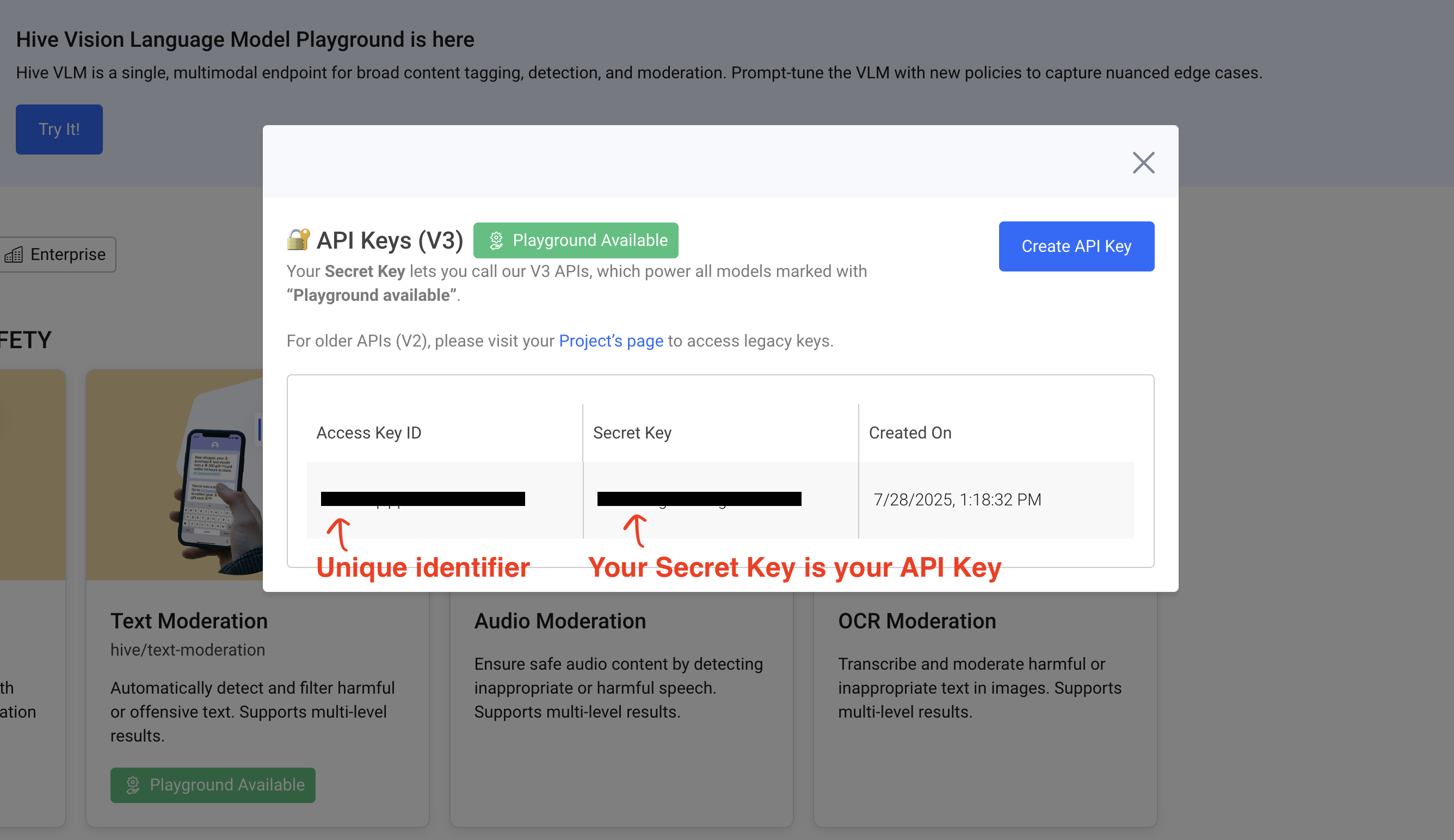
Once you've created an API Key, you can submit API requests using the Secret Key.
Please keep your Secret Key safe.
Querying Hive Vision Language Model
Hive offers an OpenAI-compatible Rest API for querying LLMs and multimodal LLMs. Here are the ways to call it:
- Using the OpenAI SDK
- Directly invoking the REST API
Using this API, the model will successively generate new tokens until either the maximum number of output tokens has been reached or if the model’s end-of-sequence (EOS) token has been generated.
Note: Some fields such as top_k are supported via the REST API, but is not supported by the OpenAI SDK.
For help writing prompt guidelines to achieve your specific use case, feel free to reach out to us with more information about your company's use case!
Using the OpenAI SDK
from openai import OpenAI
# Configure the client with custom base URL and API key
client = OpenAI(
base_url="https://api.thehive.ai/api/v3/", # Hive's endpoint
api_key="<YOUR SECRET KEY>" # Replace with your API key
)
def get_completion(prompt, model = "hive/vision-language-model"):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"
}
}
]
}
],
temperature=0.7,
max_tokens=1000
)
# Extract the response content
return response.choices[0].message.content
get_completion("What's in the image?")const OpenAI = require('openai');
let openai = new OpenAI({
apiKey: '<YOUR API KEY>',
baseURL: 'https://api.thehive.ai/api/v3/'
});
async function main() {
const completion = await openai.chat.completions.create({
model: 'hive/moderation-11b-vision-language-model',
messages: [
{
role: 'user',
content: [
{ type: 'text', text: "What's in this image?" },
{
type: 'image_url',
image_url: {
url: 'https://dash.readme.com/project/thehiveai/v1.0/docs/llama-32-11b-vision-instruct'
}
}
]
}
],
});
console.log(completion.choices[0]?.message?.content);
}
main();Directly invoking the REST API
All LLMs and Multimodal LLMs support this basic completions REST API.
curl --location --request POST 'https://api.thehive.ai/api/v3/chat/completions' \
--header 'authorization: Bearer <SECRET_KEY>' \
--header 'Content-Type: application/json' \
--data '{
"model": "hive/vision-language-model",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you describe what is in this photo?"
},
{
"type": "image_url",
"image_url": {
"url": "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"
}
}
]
}
]
}'After making a request, you’ll receive a JSON response with the model's output text. Here’s a sample output:
{
"id": "12345-be90-11ef-8469-67890",
"object": "chat.completion",
"model": "hive/vision-language-model",
"created": 1734671183762,
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The image depicts a soccer ball situated on a lush green field, with a stadium in the background. The soccer ball is positioned in the foreground, featuring a white base with vibrant blue, red, and green accents. It rests on a well-manicured grass pitch, which is neatly trimmed and maintained.\n\nIn the background, a large stadium is visible, characterized by its tiered seating and metal framework. The sky above is a brilliant blue, dotted with a few wispy clouds. The overall atmosphere suggests a daytime setting, likely during a match or practice session. The presence of the soccer ball and the stadium implies that the image was taken at a sports venue, possibly during a professional or amateur game."
},
"finish_reason": "finish"
}
],
"usage": {
"prompt_tokens": 6420,
"completion_tokens": 142,
"total_tokens": 6562
}
}Schema
Below are the definitions of possible relevant input and output fields. Some fields have default values that will be assigned if the user does not assign a value themselves.
Input
Field | Type | Definition |
|---|---|---|
messages | array of objects | Required. A structured array containing the conversation history. Each object includes a role and content. |
model | string | Required. The name of the model to call. |
role | string | The role of the participant in the conversation. Must be system, user, or assistant. |
content | string OR array of objects | Your content string. If array, each object must have a |
text | string | Referenced inside content arrays, containing the text message to be sent. |
image_url | object | Contains the image URL when type is |
max_tokens | int | Limits the number of tokens in the output. Default: 2048. Range: 1 to 2048. |
temperature | float | Controls randomness in the output. Lower values make output more deterministic. |
top_p | float | Nucleus sampling parameter to limit the probability space of token selection. Default: 0.95. |
top_k | int | Limits token sampling to the top K most probable tokens. |
Output
| Field | Type | Definition |
|---|---|---|
| id | string | The ID of the submitted task. |
| model | string | The name of the model used. |
| created | int | The timestamp (in epoch milliseconds) when the task was created. |
| choices | array of objects | Contains the model’s responses. Each object includes the index, message, and finish_reason. |
| usage | object | Contains token usage information for the request and response. |
Example messages array with multiple roles
messages array with multiple rolesWhen submitting messages to the model, you can assign different roles to your content:
- system
- user
- assistant
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant that provides detailed descriptions of images and answers user queries concisely."
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Can you describe this image in detail?"
},
{
"type": "image_url",
"image_url": {
"url": "https://d24edro6ichpbm.thehive.ai/example-images/vlm-example-image.jpeg"
}
}
]
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "The image depicts:"
}
]
}
]
Common Errors
Each model has a default starting rate limit of 5 requests per second. You may see this error below if you submit higher than the rate limit.
To request a higher rate limit please contact us!
{
"status_code": 429,
"message": "Too Many Requests"
}A positive Organization Credit balance is required to continue using Hive Models. Once you run out of credits requests will fail with the following error.
{
"status_code":405,
"message":"Your Organization is currently paused. Please check your account balance, our terms and conditions, or contact [email protected] for more information."
}